LLaDA2.0-Uni#
LLaDA2.0-Uni is a multimodal model that accepts text and image input. This SGLang-Omni cookbook covers the experimental text-output serving path.
Highlights#
Unified dLLM-MoE Backbone — Built on LLaDA 2.0, unifying multimodal understanding and generation.
Top-Tier Understanding & Generation — Matches dedicated VLMs in visual QA and document understanding, while generating high-quality images.
Interleaved Generation & Reasoning — Empowered by unified discrete representations, unlocking interleaved generation and reasoning.
Architecture#
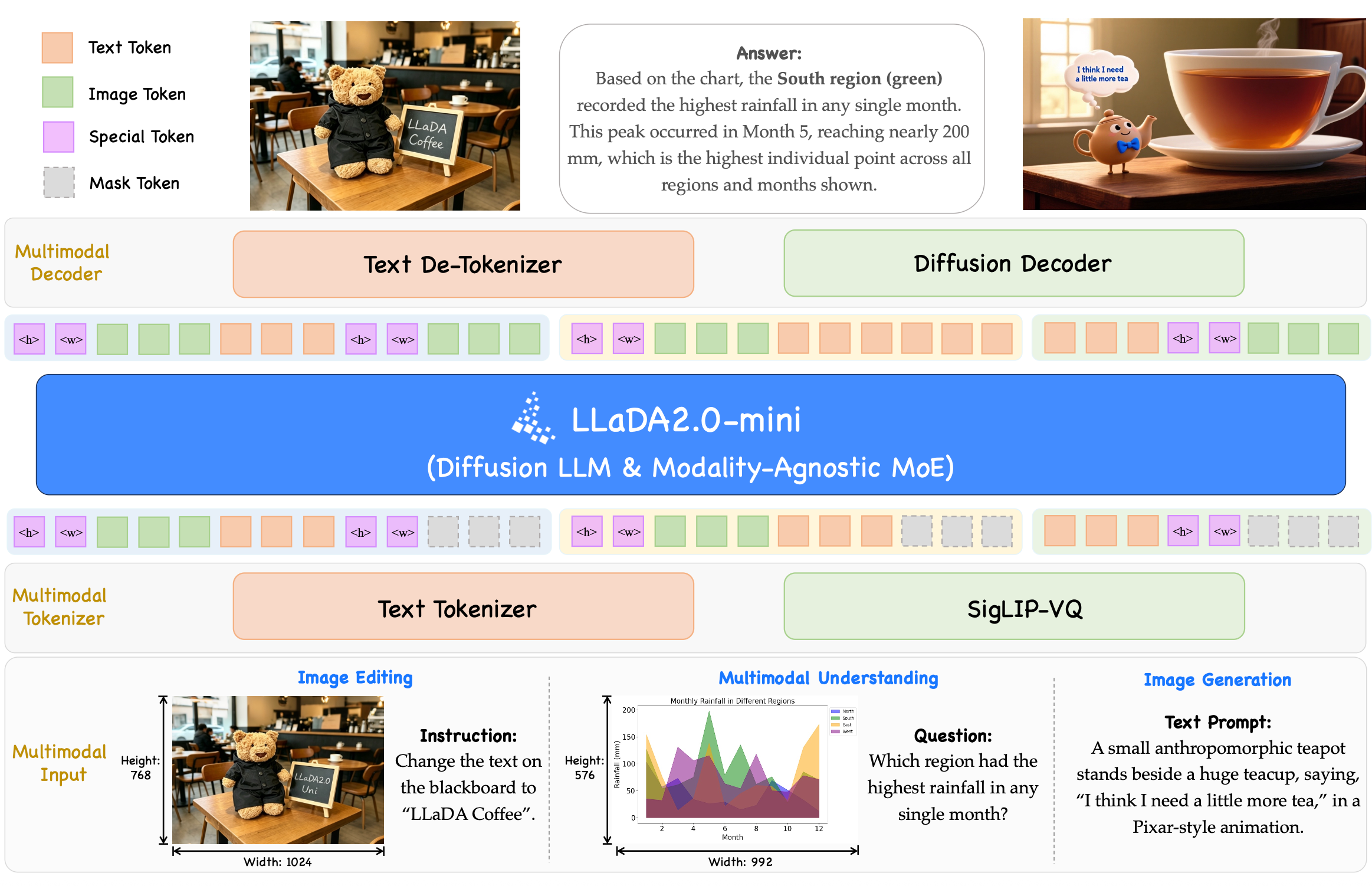
LLaDA2.0-Uni unifies multimodal understanding and generation into a simple Mask Token Prediction paradigm. Visual inputs are encoded by the SigLIP-VQ tokenizer into discrete semantic tokens, then mapped alongside text tokens to backbone hidden states under a unified mask prediction objective. Output tokens are decoded back to text via the Text De-Tokenizer, or reconstructed into high-fidelity images through the Diffusion Decoder. Empowered by unified discrete representations, it effortlessly handles complex interleaved generation and unlocks advanced interleaved reasoning, interleaving <|image|>…<|/image|> chunks to enable end-to-end training and inference within a single coherent framework.
Prerequisites#
Install sglang-omni by following Installation.
Server Configuration#
LLaDA2.0-Uni runs a 4-stage pipeline
(preprocessing → image_encoder → thinker → decode) on a single GPU. The
thinker disables CUDA graph by default for this experimental DLLM path.
sgl-omni serve --model-path inclusionAI/LLaDA2.0-Uni --port 8000
Text Input#
Send a text-only prompt and get a text response.
cURL
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "inclusionAI/LLaDA2.0-Uni",
"messages": [{"role": "user", "content": "Hello!"}],
"max_tokens": 256
}'
Python
import requests
resp = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "inclusionAI/LLaDA2.0-Uni",
"messages": [{"role": "user", "content": "Hello!"}],
"max_tokens": 256,
},
)
resp.raise_for_status()
result = resp.json()
print(result["choices"][0]["message"]["content"])
Image and Text Input#
Send an image with a text prompt to get a text response.
cURL
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "inclusionAI/LLaDA2.0-Uni",
"messages": [{"role": "user", "content": "Briefly describe the cars in this image."}],
"images": ["tests/data/cars.jpg"],
"modalities": ["text"],
"max_tokens": 16
}'
Python
import requests
resp = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "inclusionAI/LLaDA2.0-Uni",
"messages": [{"role": "user", "content": "Briefly describe the cars in this image."}],
"images": ["tests/data/cars.jpg"],
"modalities": ["text"],
"max_tokens": 16,
},
)
resp.raise_for_status()
result = resp.json()
print(result["choices"][0]["message"]["content"])
Images can also be passed inline using the OpenAI multi-content format:
import requests
resp = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "inclusionAI/LLaDA2.0-Uni",
"messages": [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "tests/data/cars.jpg"}},
{"type": "text", "text": "Briefly describe the cars in this image."},
],
}
],
"modalities": ["text"],
"max_tokens": 16,
},
)
resp.raise_for_status()
result = resp.json()
print(result["choices"][0]["message"]["content"])
Request Parameters#
The table below lists all parameters accepted by the /v1/chat/completions endpoint for LLaDA2.0-Uni.
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
string |
|
Model identifier |
|
list |
(required) |
List of chat messages, each with |
|
list |
|
Output modalities (only |
|
list |
|
List of image file paths (local paths or URLs) |
|
int |
|
Maximum number of tokens to generate |
Incoming Features#
Text-to-image generation
Text-to-Image Generation with Thinking
Interleaved Generation
Known Limitations#
Text output is supported for text and image input. Image generation and interleaved generation are not wired to the OpenAI-compatible response path yet.